After trying to find a way to run XBMC fullscreen in second monitor I decided a bespoke solution was the way forward.
UPDATE: This post was written back in the times of Ubuntu 12 (I think). As such as as you can see from the comments at the bottom of the post there are now better ways of accomplishing this task.
Although this tutorial focuses on the XBMC Media Center it can be applied to many other programs.
I know there have been work-arounds for previous versions of Ubuntu but over the years they have fallen by the wayside.
What I’m going to show you now will allow you to run XBMC fullscreen in second monitor.
Points to Note
- If you want to copy the code I advise you to click on the word “bash” above the code, this will open up a new box for you to copy the correct code from
- This tutorial is to get XBMC running in fullscreen but the code can be used to get many other programs running in fullscreen
- I have structured the tutorial so that you can run XBMC fullscreen in second monitor but you can easily alter the code to have it fullscreen in your primary monitor
- Quiet a bit of this tutorial uses the terminal, you can open a Terminal window by pressing control (or command for MacOS), Alt & T at the same time
Step 1: Run XMBC and get the title
Run XBMC up so that we can find the title it uses.
To find the title type
wmctrl -l
into the terminal. This will bring up a list of windows that the window controller is in charge of.
The chances are that the XBMC window is called “XBMC Media Center” but it may be different on yours so look in the last column of the output and copy the XBMC title.
Step 2: compizConfig settings manager
See if you have compizConfig installed by typing
which ccsm
If you get a path to the executable such as
/usr/bin/ccsm
then you have it installed. If not type
sudo apt-get install compizconfig-settings-manager
Now you can start the program by entering
ccsm
in the terminal window.
Once the program has loaded look on the right hand side and under “Effects” click “Window Decoration”
Now find the field titled “Decoration windows” and click on the green plus icon on the right hand side.
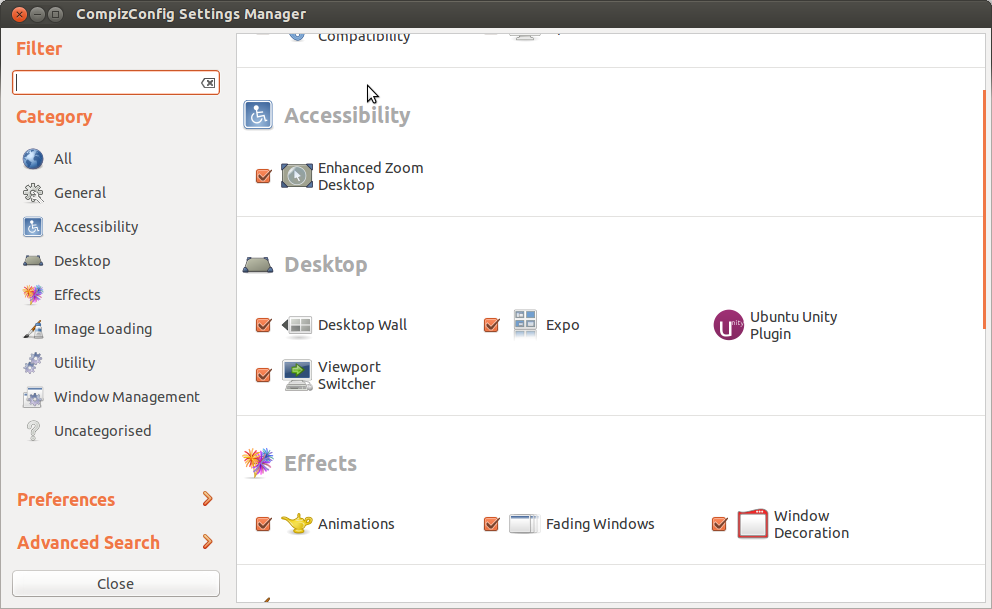
In the first drop down box select “Window Title”
In the second box enter the title that the previous step displayed
Click the “Invert” checkbox and click Add
Once that box disappears you can exit that program.
What this does is hide the title bar from from the XBMC window
Step 3: Get your display information
Now we need to get the display details
Run xrandr from the terminal
xrandr | grep " connected" | sed -e 's/\(.*\) connected \(.*\) (.*/\nDisplay Name: \1\nDisplay Sizes: \2 /'
You will be presented with an output similar to the following
Display Name: VGA-0
Display Sizes: 1440x900+0+0
Display Name: DVI-I-1
Display Sizes: 1680×1050+1440+0
Assuming you’re wanting the program in your second monitor then we the information from the latter of the two monitors
The display name is straight forward – take a note of this.
The next line not to straight forward. The value is made up of
display-width x display-height + start-x-pxs-from-the-left + start-x-pxs-from-the-top
The value we need here is the third value as this will be where the XBMC window will start (from the left)
Step 3: Create out actual script file
Create a file called….well, what ever you want, I called mine XBMC_fullscreen.sh
In this file type or paste the following:
Now you need to change the NAME variable to something other than the default value **IF** your version of XBMC has a different title in the window (see last step).
You also need to change the DEVICE variable to the one returned as Display Name above.
Lastly you need to change the PRIMARYWIDTH variable to the third number in the returned Display Sizes above.
Now let’s take a look at what this does (just the important lines though)
#!/bin/bash- This tells the system to use bash to execute the script
PROGRAM='xbmc'- Set the program to the path we found earlier
NAME='XBMC Media Center'- This sets the title of the the window that we want to control
DEVICE='DVI-I-1'- This is the name of the display device that we noted down earlier
PRIMARYWIDTH='1440'- This is the width of your primary monitor
$PROGRAM > /dev/null 2> /dev/null & disown && sleep 3- Ok, this line will:
- Start the program
- Redirect the output
- Disown the process so that the the script can carry on
- Wait 3 seconds so the program has a chance to start
__GL_SYNC_TO_VBLANK=1- Set the vertical line blanking to on
__GL_SYNC_DISPLAY_DEVICE="$DEVICE"- Make sure that we tie our XBMC window to the device we want
SDL_VIDEO_ALLOW_SCREENSAVER=0- Make sure we don’t have the screensaver
wmctrl -r "$\$NAME" -e '0,"$PRIMARYWIDTH",-1,-1,-1'- This will set the window to start at the end of the primary monitor
wmctrl -r "$\$NAME" -b toggle,fullscreen,maximized_vert- This will put the window in full screen but we also need to maximize the window vertically
Step 5: Save the file
Now we need to save the file and make it executable.
I’m sure you know how to save a file but then once it’s saved go back into the terminal and type
chmod +x
So for me it was
chmod +x ~/xbmc_fullscreen.sh
Step 6: Create a shortcut
If you haven’t already got it, install gnome-panel
sudo apt-get install --no-install-recommends gnome-panel
Now type
gnome-desktop-item-edit ~/Desktop/ --create-new
This will bring up a box that will enable us to add a shortcut to the desktop. We can then drag and drop it on the launcher.
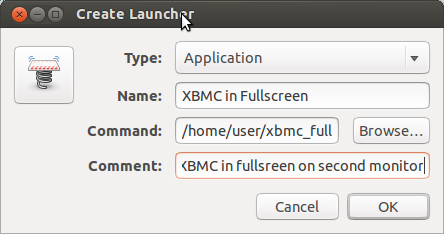
Ok, so
In the “Type” box leave the default value (Application)
In Name type anything you like, I typed “Run XBMC in Full Screen”
In the 3rd box type the path to our shell file in the form of /home/user/xbmc_fullscreen.sh
If you want to type any comments in the last box then feel free.
Take a look on your Desktop and you should now have a shortcut to XBMC that works as default in full screen.
If you want, simply drag this shortcut over the launcher to the side of the screen.
That about does it for this script.
That’s it, thanks for looking, I hope you enjoyed the post and don’t forget to leave your comments below.
Update
At some point further down the line the above script stopped working for me. It appears as if it needed a bit of a timeout so I often had to run a script containing these commands. This basically goes through the previous proceedure but as the XBMC program is already running it just sets the GUI co-ords etc.
PROGRAM='XBMC'
NAME='XBMC Media Center'
DEVICE='DVI-I-1'
PRIMARYWIDTH=1440
__GL_SYNC_TO_VBLANK=1
__GL_SYNC_DISPLAY_DEVICE="$DEVICE"
SDL_VIDEO_ALLOW_SCREENSAVER=0
wmctrl -r "$NAME" -e '0, '$PRIMARYWIDTH',-1,-1,-1'
wmctrl -r "$NAME" -b toggle,fullscreen,maximized_vert
If you have run the first part of the post but XBMC is still in your primary monitor then try this part. Hopefully your system just needed a bit of a timeout before the wmctrl commands were set.
how about for windows?
Hi,
Sorry to take so long to reply. Unfortunately I haven’t used Windows in years and so I have no idea how you would accomplish this. Hopefully you manage to solve the Windows issue.
Sorry again,
John
Grate tutorial!!! But there is one thing I need help with.. my second monitor is on the left so I think I need to change this line a bit:
wmctrl -r “$\$NAME” -e ‘0,”$PRIMARYWIDTH”,-1,-1,-1’
my screen settings:
Display Name: LVDS1
Display Sizes: 1280×800+1360+0
Display Name: HDMI1
Display Sizes: 1360×768+0+0
It works perfectly when I place my second monitor on the right.. but not on the left..
Can you help me please?
Hi Kristjan,
This is just a quick reply but I’ve just noticed that the version I have on here differs from the one I use on my machine. Can you change the lines with
“$\$NAME”
to
“$NAME”
Does that make any difference? If not I’ll look into it further.
Regards,
John
i followed al insrttuction you provided and still onty palyer on my monitor not on my flat scree :
#!/bin/bash
# This script will run a program in fullscreen mode (no borders or
# title bar etc) on a second monitor. It can used for many programs
# and on either the primary or secondary monitor
#This is the executable file or path
PROGRAM=’xbmc’
# This is the output of wmctrl -l for the program that we are using
NAME=’XBMC Media Center’
# This is the device name of the monitor we want to display the program on
DEVICE=’HDMI-0′
# If you want the program to be fullscreen on your second monitor
# this variable should be the width of your primary monitor
PRIMARYWIDTH=1920
# Run the program , then wait a bit before carrying on
# If your program doesn’t load in time then try increasing this value
$PROGRAM > /dev/null 2> /dev/null & disown && sleep 3
## Set the Open GL environment variables
# Set the vertical blanking to on
__GL_SYNC_TO_VBLANK=1
# And make sure OpenGL syncs the correct monitor
__GL_SYNC_DISPLAY_DEVICE=”$DEVICE”
# Do we want a screensaver
SDL_VIDEO_ALLOW_SCREENSAVER=0
# Set the dimensions of the program in the monitor
wmctrl -r “$NAME” -e ‘0,’$PRIMARYWIDTH’,-1,-1,-1′
# Maximize it
wmctrl -r “$NAME” -b toggle,fullscreen,maximized_vert
followed everthing else the short cut works fine but it opens xbmc on my destop monitor instead of my flat screen tv any help is always welcome
Hi Carl,
Are you still suffering with this problem? I’m about to post an update the the original post with the problem that I encountered further down the line. This may help you.
John
I followed this, thanks I learned a few things!
However it starts on my main monitor. I have an off setup where my second screen is above and half way to the right of the main.
Display Name: HDMI-0
Display Sizes: 1920×1080+881+0
Display Name: DVI-D-0
Display Sizes: primary 1920×1080+0+1080
I used 881 as my third number, and tried 0. Both came out the same. Any idea how to fix this. I’ve been trying to get separate xscreens working but cant find a good guide.
Thanks,
Noki
Hi Noki,
Is this something that is still bothering you or have you solved it? I’m about to post an update to my original post that may help.
John
Hi Author Grandad,
Just want to say I followed your tutorial and it works an absolute treat! If I run the script via terminal it sets the application to fullscreen on my TV and I can’t believe it!
What a fine piece of work you’ve done there, I can’t thank you enough!
No more grey bars on my TV, you have made my day!
Kind Regards,
Marcus.
Hi Marcus,
WOW! Thank you so much. That is a great compliment and much appreciated. There are people who cannot get this script to work, not through any fault of there own but it just doesn’t suit some systems. Even I have had to apply a subsequent script that applies a timeout before going full screen.
Again: thank you for the brilliant feedback.
Grandad (John)
I’m on Linux mint 17. This seems to work for me but the audio stays on my computer speakers, no matter the setting I use in system/audo output in xbmc. Do you have any idea how to shift it to the TV speakers?
Hi Stephen,
I’m afraid I cannot help you with that. It took a bit of work to get to the point of this post but as for sound I am not able to comment on that.
Sorry but thanks for reading 🙂
John (Grandad)
Care to update for the change to Kodi?
Hi Joe,
Sorry but I haven’t used XBMC for a while now but when I do I’ll have a look at it and see what I can do.
Many thanks for leaving a comment though. It’s much appreciated.
John
Hello again Joe,
I will now be updating this post over the next few weeks to a month.
I hope you found a solution though.
I wasnt paying attention & leaned on my mini keyboard and my XBMC screen has minimized. How do I maximize it?
How do
Hi Cassandra,
Assuming you are on Linux/Ubuntu have you tried the keyboard shortcuts to maximize windows? For me this is CTRL + Windows key + up key
There are quite a few good tips at this askUbuntu page (What are Unity’s keyboard and mouse shortcuts?)
Hi, Thanks for the tips. Question: Is this still the best way to go, as of this date? I ask only because there have been updates to both the OS and XBMC since.
Hi, thanks for the comment.
I am not too sure to be honest. It seems from playing about the other day that the latest update to Unity has ruined this post.
The Window Decoration window no longer works as it conflicts with the Unity plugin. That means that currently I cannot get the title bar to be removed.
I am looking for alternatives but at the minute I have a massive personal project on the go as well which means that I only get the odd bit of time to look at this post and alternative solutions.
You don’t need the cssm stuff. It worked for me only using the script (14.10)
I am running KODI on Xubuntu 14.10 with an extended dual screen setup. When running KODI in windowed mode on the second screen, I simply right-click the title bar of the KODI window and chose fullscreen mode. That’s it.
Thanks, that helped. Old XMBC was not able to go full screen properly with two monitors attached. Works fine with Kodi.
Hi Serrano,
I do seriously need to update this post! It looks like this works “out of the box” with Kodi but as you rightly pointed out it usually works when working with old systems.
Thanks for your comment and I’m glad it helped in some way.
Thanks!!By the way the cssm stuff is not needed. Unity plugin is broken with that plugin(14.10) but it worked without adjusting that!!Thanks!!